CODA.BR 2021 se firma como maior conferência de Jornalismo de Dados da América Latina
Compartilhar

Texto e Imagens: Eduardo Fabricio e Isabelle Vita Gregorini (2º semestre)
Entre os dias 8 e 13 de novembro ocorreu a sexta edição da maior conferência de Jornalismo de Dados da América Latina, o CODA.BR. O evento, realizado juntamente com a Escola de Dados e a Open Knowledge Brazil, e desenvolvido pela Google News Initiative, conta com o apoio de empresas como a ABRAJI e de instituições como a ESPM, UOL e Knight Center.
A conferência, realizada de forma totalmente online, contou com dezenas de atividades ao vivo ao longo da semana, sendo 30 horas de workshops, seis atrações principais – divididas em três keynotes e três painéis de debate – e 18 apresentações inspiratórias durante a entrega do Prêmio Cláudio Weber Abramo de Jornalismo de Dados, que finalizou o evento.
Veja a cobertura completa:
Segunda-feira
Workshop: Criando portais de dados abertos – usando CKAN como parte do Data OS
Na tarde de segunda-feira (08) ocorreu o terceiro evento realizado durante a sexta edição da Conferência Brasileira de Jornalismo de Dados e Métodos Digitais. O workshop, que tinha como tema ‘’Criando portais de dados abertos: usando CKAN como parte do Data OS’’, contou com a presença especial de Anuar Ustayev, líder de produto e engenheiro de software sênior da Datopian, e foi mediado por Fernanda Campagnucci, diretora executiva da Open Knowledge Brazil.
No início do workshop, Anuar deu uma leve introdução sobre o que é o Data OS e como o CKAN (Comprehensive Knowledge Archive Network) funciona dentro desse sistema. O engenheiro de software explicou, inclusive, que o CKAN é uma ‘’aplicação web de catalogação de dados elaborada pela Open Knowledge Foundation’’.
Durante o evento, Anuar também demonstrou como funciona o CKAN e apresentou empresas e plataformas que foram desenvolvidas a partir dessa ferramenta, como a EnergiNet (empresa pública de produção de energia e gás natural na Dinamarca) e o Data.gov (site americano com dados dobre diversos assuntos e um dos primeiros portais de dados desenvolvido a partir do CKAN).
O engenheiro, inclusive, exemplificou como funciona o software do CKAN, apresentando os meios de navegação dentro do mesmo, como os dataset, a criação de grupos e as atividades.
Já no fim do workshop, a mediadora Fernanda abriu um espaço para que os telespectadores tirassem suas dúvidas com Anuar, e, após as questões serem respondidas, Fernanda finalizou agradecendo a presença do engenheiro e a atenção dos telespectadores. Anuar também agradeceu os telespectadores e o evento pelo convite, além de, inclusive, dizer ao público que estava aberto a ideias e sugestões de melhorias no software.
Keynote: Como o Jornalismo e a Tecnologia podem trabalhar juntos em prol de mais transparência
Na noite de segunda-feira (08), aconteceu o primeiro keynote da sexta edição da Conferência Brasileira de Jornalismo de Dados e Métodos Digitais. O evento que teve como tema: ‘’como o Jornalismo e a Tecnologia podem trabalhar juntos em prol de mais transparência’’ contou com a ilustre presença de Jim Albrecht, diretor de produtos do ecossistema de notícias do Google, e foi mediado por Marco Túlio Pires, coordenador do Google News Initiative no Brasil.
Jim teve como foco principal durante toda sua apresentação a demonstração da importância da transparência no Jornalismo e a necessidade do uso da tecnologia para obter tal transparência. O diretor ressaltou, inclusive, a importância na apuração de dados antes da divulgação do mesmo, e citou a relevância que o mecanismo de função de busca do Google possui durante as apurações.
A semelhança entre a indústria da tecnologia e a mídia jornalística também foi um ponto muito discutido por Jim, que pontuou: “O que as duas indústrias têm em comum é que, à sua maneira, as duas ‘seguem o dinheiro’. Jornalistas fazem isso para descobrir o exercício oculto do poder, já a indústria tech faz isso para patrocinar seu último entusiasmo. Ou melhor, os próprios entusiasmos são movidos pelo fluxo de capital”.
O diretor continuou abordando sobre a importância do dinheiro investido e aplicado em sucessos, além de fazer uma leve crítica ao sistema de investimento ao acesso de dados na atualidade, relatando um ocorrido na sua carreira profissional, criticando o fato de dez vezes mais dinheiro ir para direcionamento de anúncios do que para direcionamento de matérias jornalísticas e pontuando: “‘Eu não ligo’ é a resposta padrão do capital para as demandas da sociedade civil. O capital não está nem aí! Ele só liga para o dinheiro dos acionistas”.
Por fim, o mediador Marco abriu para as perguntas destinadas ao Jim e, após serem respondidas, Marco agradeceu a presença do diretor. Jim, consequentemente, agradeceu o convite e a audiência dos telespectadores, reiterando a importância dos jornalistas dentro do mundo de dados.
Terça-feira
Workshop: Explorar e visualizar dados – ajuste suas pautas
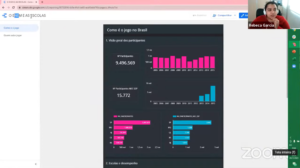
A manhã da terça-feira começou com a atividade “Explorar e visualizar dados: ajuste suas pautas”, mediada por Anicely Santos, apoiadora pedagógica da Escola de Dados, e apresentada por Rebeca Garcia, jornalista pela UnB e gerente de performance na Street Mídia. O workshop consistiu na criação de um dashboard que reúne gráficos com dados sobre o Enem de 2008 a 2015. A base de dados foi retirada diretamente do site do Inep.
Data Studio foi a ferramenta usada no webinar por ser completamente gratuito, online, ter apoio da comunidade e ser intuitiva, como classificou a apresentadora. Rebeca começou apresentando as quatro etapas, do que chamou de narrativa de dados.
A primeira é definir a base de dados, no caso, a do Enem. Para isso, é necessário saber sua origem, entender seu formato e conhecer as variáveis. O próximo passo é construir as perguntas, decidir o que a base irá responder. Explorar a base é o terceiro passo, é necessário decidir quais dados necessitam de gráficos e quais podem ser explicados apenas com uma tabela. Por último, constrói-se a narrativa, sempre pensando no público-alvo.
As perguntas que orientaram a criação do dashboard foram: o número de participantes está aumentando ao longo dos anos? Qual ano com maior número de participantes? Qual a Unidade Federativa (UF) com melhor desempenho médio por matéria? Escolas de maior porte resultam em notas mais baixas? Quais as escolas por UF com melhor desempenho?
Depois a jornalista apresentou algumas características que facilitam a visualização e entendimento dos gráficos, como cor, escala, tamanho, ordem das variáveis etc. Também apontou alguns erros comuns que se pode cometer na construção de dados. Rebeca ainda destacou que é necessário aprender a executar o básico antes de partir para construções mais complexas.
Para começar a construção, a apresentadora falou sobre a importância do dicionário de uma base de dados, segundo ela, às vezes o nome da variável não é autoexplicativo. Rebeca explicou a construção de gráficos de colunas, barras e rosca, de acordo com a melhor visualização para cada um.
Ao fim, o dashboard contou com uma página sobre o Enem, voltada para estatísticas gerais. A segunda página focou no desempenho por UF e escolas, destacando os melhores resultados em cada variável. A jornalista disse que essa prática facilita na construção de eventuais pautas, seja para a publicação direta ou para consulta interna dos jornalistas dentro da redação. Rebeca finalizou a apresentação expondo algumas referências do exterior e brasileiras, como o Nexo Jornal e a Agência Lupa.
Workshop: Ferramentas para mitigar vieses em Inteligência Artificial
Durante a tarde, das 14h até 15h30, aconteceu o workshop “Ferramentas para mitigar vieses em Inteligência Artificial (IA)”. O evento foi mediado por Gabriela de Queiroz, cientista-chefe de dados da IBM Califórnia, contou com a apresentação de Paolla Magalhães, cientista de dados atuante na indústria de alimentos, e com uma breve fala de Adriano Belisário, coordenador da Escola de Dados.
A presença de viés em amostras de dados as configura como um modelo discriminatório. O objetivo da atividade foi ensinar, utilizando o kit de ferramentas de código aberto AI Fairness 360 (AIF 360) em Python, como medir e suavizar esses vieses. Mas antes da prática, Gabriela apresentou algumas definições de terminologias comuns à ciência de dados, para facilitar a compreensão dos menos familiarizados. Logo após, cedeu a palavra para Paolla dar início ao workshop.
A cientista de dados apresentou passos preliminares antes do processo de ajuste da amostra. O primeiro deles é a definição do problema, que consiste em decidir qual ou quais são os atributos sensíveis. Atributo sensível é o fator determinante para o privilégio ou não de determinado grupo da amostra.
Ela citou como exemplo a engenharia, profissão em que apenas 28,1% dos profissionais são mulheres, segundo dados publicados em 2017 pelo Conselho Federal de Engenharia e Agronomia (CONFEA). Neste caso, há um privilégio dos homens, onde o atributo sensível é o sexo.
Paolla também destaca que o trabalho é praticamente uma “quantificação da justiça” já que a máquina só entende números. Para isso, é usada a matriz de confusão, um cruzamento entre a resposta dada pelo computador e a resposta esperada na realidade.

Ela finalizou a parte teórica pontuando que a mitigação do viés pode ser feita tanto antes, durante ou depois do processamento e treinamento do modelo por parte da máquina. Segundo ela, a escolha de qual técnica será usada depende do caso específico.
Para a atividade prática, foi usada uma amostra de dados com mais de 30 mil linhas. A análise consistia em identificar, usando o AIF 360 aplicado no Google Colab, se havia viés, fatores que determinassem se certo morador dos EUA recebe ou não salário anual superior a US $50 mil.
Ao fim do workshop, constatou-se que a amostra estava enviesada, principalmente pelo sexo e raça dos participantes. A suavização do viés foi feita pela Paolla e o processo acompanhado ao vivo pelos telespectadores da webinar, que puderam fazer perguntas durante todo o evento.
Workshop: Dados e saúde – SIVEP sem segredo
Durante a tarde de terça-feira (09), segundo dia da sexta edição da Conferência Brasileira de Jornalismo de Dados e Métodos Digitais, ocorreu o workshop “Dados e saúde: SIVEP sem segredo”.
O workshop foi mediado por Anicely Santos, analista de dados, e contou com a presença especial de Ana Carolina Moreno, jornalista de dados sênior da TV Globo, e Raphael Saldanha, cientista de dados em saúde pela Fiocruz.
O foco principal do evento foi ensinar e analisar o SIVEP, base de dados sobre Síndromes Respiratórias Agudas Graves (SRAG) e a mais útil para cobrir o Covid-19 no Brasil. Durante o workshop, os convidados mostraram aos telespectadores como filtrar e analisar tantos dados sobre tal assunto.
Após Anicely apresentar os convidados e explicar como iria funcionar o evento, Raphael começou a introduzir o assunto do workshop. O cientista explicou o que eram notificações de síndromes respiratórias agudas graves, mostrou como funciona a coleta dos dados que o SIVEP possui, além de, também, apresentar gráficos e tabelas relacionados a estágios e dados de tais síndromes, como quando o indivíduo espirrou pela primeira vez, ou quando foi internado.
Após a apresentação de Raphael, Ana Carolina explicou aos telespectadores como funcionava a base do SIVEP-Gripe por meio de um passo a passo. A jornalista, inclusive, se atentou em mostrar os cuidados que os indivíduos devem ter com a base de dados, como a subnotificação e a SRAG não especificada ou o atraso de notificação.
Durante a apresentação de Ana Carolina, a jornalista demonstrou o uso do SIVEP com exemplos de estudos de casos em notícias na mídia, ligando, principalmente, com o dado utilizado e o local onde ele foi coletado dentro do SIVEP.
Além de conteúdos mais direcionados ao entendimento e a facilitação da navegação no SIVEP, os dois convidados enfatizaram a importância dos dados e da dedicação no estudo dos mesmos.
Por fim, a mediadora do workshop, Anicely Santos, agradeceu a presença dos convidados e dos telespectadores. Os convidados, Ana Carolina e Raphael, também agradeceram a presença dos telespectadores e o convite.
Painel: LAI em tempos de LGPD
O primeiro painel do Coda tratou sobre a relação entre a Lei de Acesso à Informação (LAI) e a Lei Geral de Proteção de Dados (LGPD). O evento foi mediado por Fernanda Campagnucci, diretora-executiva da Open Knowledge Brasil, e contou com a participação de Maria Vitória Ramos, cofundadora e diretora da Fiquem Sabendo, Jamila Venturini, diretora-executiva da Derechos Digitales e Paulo Rená, professor de Direito, Inovação e Tecnologia na Faculdade de Ciências Jurídicas e Sociais do Centro Universitário de Brasília (CEUB).
O painel aconteceu das 19h até às 20h30 e cada participante fez uma apresentação de 15 minutos, começando por Jamila Venturini. Ela começou fazendo um panorama geral sobre leis de acesso à informação em países da América Latina. A jornalista destacou que a transparência da coleta e uso dos dados é uma alternativa para o desafio que é equilibrar o acesso à informação e a proteção de dados. “É interessante pensar que, ainda que sejam direitos fundamentais, que por vezes estão em conflito, um também é fundamental para o outro”.
Ela disse que é inaceitável que se mantenham choques entre o acesso à informação e privacidade dos dados, principalmente em uma região onde ainda prevalece uma cultura de segredo. “A gente não pode cair num discurso oportunista que tenta continuar promovendo abusos longe da supervisão pública e para isso cria essas falsas tensões”.
Jamila concluiu que é necessário se aprofundar nas ferramentas que existem para equilibrar esses direitos em cada caso específico. “As LGPDs não foram feitas para afetar o exercício legítimo do jornalismo. Não existe democracia sem acesso à informação pública, nem igualdade sem que a sociedade possa se proteger dos usos abusivos de seus dados e da intrusão indevida do Estado”, completou.
Paulo Rená deu continuidade ao painel falando que uma das principais funções do instituto Beta, a qual faz parte, é usar a internet para aprimorar a democracia. Logo após declarou que no Brasil existe uma inversão nos fluxos das duas leis. Para explicar isso, ele contou o contexto e a trajetória de ambas as leis até terem a configuração conhecida hoje.
Paulo também destaca que a LGPD vem com um atraso do Brasil em relação ao mundo, já que no país não há esse histórico de proteção dos dados pessoais. O professor fala que junto à lei, é necessária uma mudança cultural, pois ela traz as regras e demanda mecanismos para a implementação em empresas, poder público etc.
“A questão da proteção de dados não se limita justamente só à privacidade, porque não demanda sigilo. Um dos pontos principais é que os dados não sejam usados fora da finalidade para qual foram coletados”, explicou. Ele finaliza dizendo que a LGPD não é uma lei de proibição de uso a dados pessoais ou de acesso à dados públicos, mas sim uma lei voltada à proteção.
Maria Vitória começou falando que o Fiquem Sabendo não critica a LGPD, mas sim, como ela classifica, o uso indevido dela. “É um uso indevido da legislação para manter a distância dos cidadãos de informações com caráter extremamente público”, comentou.
Ela citou um levantamento feito pelo jornalista Eduardo Goulart, para a Fiquem Sabendo, de todas as negativas de pedido de acesso à informação da LGPD que chegaram até a Controladoria Geral da União (CGU). Foram 79 até agosto deste ano, mas ela alerta que poucos casos chegam até a CGU, pois a maioria para na primeira ou segunda instância.
Maria revela que o Fiquem Sabendo, junto ao Insper, fará um relatório de todas as negativas com base na LGPD já feitas. Também deu alguns exemplos de casos, como o fechamento dos relatórios de trabalho escravo e dos nomes das empresas autuadas por trabalho escravo. “As pessoas que vão julgar os casos de possíveis embates entre as legislações têm que ser conscientizadas dos dois lados, para que não haja um desbalanceamento nesse julgamento”, concluiu.
A rodada de perguntas teve questões direcionadas por Fernanda para cada um dos participantes. Possíveis impedimentos da LGPD para o trabalho jornalístico, penalidades para os órgãos que não se adequarem às leis e falta de acompanhamento da CGU nas questões envolvendo CGU foram alguns dos temas discutidos.
Evento na íntegra: https://www.youtube.com/watch?v=0HNmlHd5KD8&t=3725s
Quarta-feira
Workshop: Índice Folha de Equilíbrio Racial
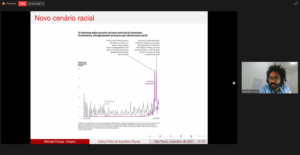
O workshop “Índice Folha de Equilíbrio Racial” aconteceu durante a manhã, das 9h às 10h30. Adriano Belisário foi o mediador e Michael França, doutor em teoria econômica pela USP, pesquisador e coordenador do Núcleo de Estudos Raciais do Insper, foi o responsável pela apresentação do webinar. O Índice Folha de Equilíbrio Racial (IFER) é uma produção do Núcleo de Estudos Raciais em parceria com a Folha. Ele quantifica o desequilíbrio racial no Brasil a partir dos componentes: educação, envelhecimento e renda.
A fala de Michael abordou todo o processo de formação, desde a ideia e desenvolvimento até sua repercussão, tanto do IFER quanto de seu “antecessor”, o Índice de Equilíbrio Racial (IER), focado no meio empresarial. O pesquisador começou contextualizando o panorama atual em que os dois surgem. Segundo ele, o Brasil vive um novo cenário racial, motivado pela valorização da identidade negra, ampliação do acesso dos negros ao ensino superior, entre outros fatores.
Ele também destaca que o movimento negro está cada vez mais coeso e organizado, ditando pautas a serem discutidas e ganhando força na política brasileira. Porém ele alerta para um risco, uma possível polarização racial no Brasil, o que julga pouco provável, mas que ainda assim merece ser vigiada.
Depois da introdução, Michael contou como foi o processo de criação do IER. A ideia surgiu de Jair Ribeiro, que percebeu o assunto “equilíbrio racial” em evidência nas corporações do resto do mundo. A partir disso, adaptaram um estudo de mesma natureza, realizado nos EUA pós-guerra, à realidade das organizações privadas brasileiras. A principal constatação que o IER demonstra é: quão desequilibrada racialmente está a empresa ou determinado setor dela. RAIS e Pnad são as duas bases de dados usadas pelo índice. Algumas observações podem ser feitas ainda na coleta de dados, de acordo com ele, quando pessoas vão “subindo na carreira” a descrição de cor delas tende a se embranquecer.
Segundo Michael, “as empresas deveriam ser um retrato da sociedade ao seu entorno”, por isso a primeira variável usada é a população economicamente ativa de onde se localiza a empresa. Já a segunda é sobre o grupo que se quer estudar, por exemplo, o percentual de negros que ocupam a diretoria da organização. Cargos com maior salário tem maior peso na análise.
O pesquisador ainda destaca que o diferencial do índice são seus recortes, pois no Brasil existem diferentes dinâmicas raciais de acordo com a colonização, economia etc. Por isso, não faz sentido abordar todo o país como uma unidade. Isso também facilita a visualização de quais lugares avançam no equilíbrio racial, assim se pode estudar as medidas que estão influenciando nisso e replicá-las.
Michael diz que o índice serve como mecanismo de mudança de comportamento, uma vez que essas questões passam a ser discutidas e valorizadas, empresas que não têm um bom equilíbrio racial acabam saindo atrás. Esse fator já levou organizações a mudarem sua política de contratação para se adequar e balancear o índice. “Com dados, com pesquisa, se ajuda a dar uma resposta social”, completou.
Ele também revelou receber bons feedbacks sobre a repercussão do índice no meio empresarial, e que isso ajuda a estabelecer um horizonte de maior equilíbrio social no meio corporativo. Segundo ele, 30 das 500 maiores empresas do Brasil já aderiram ao IER.
O IFER consiste no mesmo mecanismo, o parâmetro de população de determinada região é mantido, mas comparado com três componentes diferentes: educação, renda e envelhecimento. A parceria com a Folha é motivada pelo veículo, que colocou a discussão racial como uma das principais pautas para o ano.
São alguns exemplos das comparações feitas: quantos negros estão entre os 10% que mais recebem no mercado de trabalho (renda); qual o percentual de negros no ensino superior (educação); dentro dos 10% da população mais idosa de um lugar, quantos são negros (envelhecimento).
Michael destaca que o último componente foi escolhido pois engloba diversas outras variáveis, como acesso a saneamento básico e saúde de qualidade, requisitos importantes para que uma pessoa viva mais tempo. A partir dessa coleta, é feita uma média simples dos três e dividida pela população de uma região ou estado. Diferente do IER, por não estar voltado para o universo empresarial, o IFER só utiliza a Pnad como base de dados.
Assim como no anterior, a coleta dos dados já apresenta alguns cenários. Segundo a Pnad, há uma tendência de equilíbrio racial no ensino superior brasileiro, porém, isso não se repete na pós-graduação. Cursos de exatas ainda apresentam desigualdade, os de humanas são mais comuns a negros. Já a renda projeta o crescimento da desigualdade, assim como o envelhecimento, ainda que em menor escala.
Michael finalizou destacando que o índice não trata de discriminação somente, mas também expõe a exclusão social que afeta os negros tanto no meio empresarial quanto na sociedade em geral. O objetivo do IFER é promover uma carteira de ações baseadas nos dados que ele apresenta.
Workshop: Dados Eleitorais – Explorando parâmetros para representar minorias
Na tarde de quarta-feira (10), aconteceu o workshop “Dados eleitorais: Explorando parâmetros para representar minoriais”. O evento foi mediado por Adricely Santos, analista de dados, e contou com a presença de Flávia Bozza, analista de dados e pesquisadora da Gênero e Número, e Marília Ferrari, designer de informação de gênero e número.
O foco do workshop foi mostrar como encontrar dados sobre minorias em plataformas de dados e, principalmente, como utilizar esses dados para aumentar a representatividade desses grupos.
Para iniciar as apresentações, Adricely apresentou as convidadas e explicou aos telespectadores como iria funcionar o evento. Logo em seguida, Flávia começou a apresentação introduzindo o assunto ao público. Explicou a importância do Tribunal Superior Eleitoral (TSE) na coleta e divulgação dos dados eleitorais e pontuou que somente em 2016 começaram a existir dados raciais.
A analista de dados ensinou aos telespectadores, por meio de um passo a passo, como navegar e encontrar dados no site do TSE, que possui um repositório de dados desde 1933. Flávia, inclusive, achou importante explicar ao público termos fundamentais dentro do meio de dados, como conjunto de dados e variáveis. Durante sua apresentação, a analista utilizou uma planilha no excel sobre os candidatos à prefeitura em 2020 (que também foi aberta por meio de um link pelo público) para explicar como achar dados na mesma. Flávia, inclusive, se mostrou indignada com a baixa quantidade de representantes de grupos minoritários dentre os candidatos.
Após a apresentação de Flávia, Marília começou sua apresentação. A designer mostrou alguns gráficos que produziu, mostrando como encontrou os dados, onde encontrou e como os utilizou dentro do gráfico. Marília se atentou em explicar aos telespectadores em como pensar antes de colocar os dados no gráfico, tendo em vista a procura, a seleção e, principalmente, a aplicação dos mesmos.
Com o fim da apresentação de Marília, Flávia agradeceu o convite e a presença de todos no workshop e se deixou à disposição caso algum telespectador queira tirar dúvidas ou entrar em contato com a mesma pelo e-mail. Logo em seguida, a mediadora Adricely agradeceu a presença das duas convidadas e do público, e, por fim, Marília também agradeceu.
Keynote: Levando o poder da visualização de dados para todos
A noite de quarta-feira terminou com o keynote “Levando o poder da visualização de dados para todos”. A atividade foi comandada por Gurman Bhatia, jornalista de dados, premiada baseada em Nova Delhi, Índia. Bárbara Castro, Diretora de Criação Ambos e Professora Doutora em Artes & Design PUC-Rio, foi a mediadora.
Todo o keynote foi apresentado em inglês, com legendas simultâneas durante a fala de Gurman. Ela iniciou apontando as quatro bases de seu trabalho: jornalismo, ensino, dataviz e programação. Também mostrou algumas variações de gráficos e formas de se visualizar dados.
A jornalista deu vários exemplos de onde o jornalismo de dados pode ser usado, desde empresas até ONGs e políticas públicas. Logo após apresentou os fatores que justificam a popularização da visualização de dados, começando com as melhores ferramentas de hoje em dia. Algumas usam códigos pequenos, e outras nem usam, facilitando o trabalho de quem é menos familiarizado com programação.
Gurman cita que a comunidade está mais forte atualmente, o que também populariza a visualização de dados. Essa comunidade se ajuda com eventuais dúvidas que surjam entre os usuários. Outra inovação importante para o processo são as fontes grátis online para aprendizado, com conjuntos de tutoriais para quem está começando.
A quarta característica da popularização são as plataformas mais visuais, em que se pode compartilhar as produções, o que segundo Gurman, incentiva os produtores. O ponto seguinte é o aumento da educação visual e de dados, que para a jornalista, está muito ligado ao anterior.
Ela também diz que está ocorrendo uma mudança gradual para técnicas de comunicação melhores, com títulos e manchetes diretas, de fácil compreensão. Por fim, ela fala que há mais dados, que coletados poderão ser visualizados, tornando a prática cada vez mais comum ao público.
Apesar de todas essas evoluções, Gurman também elenca campos que devem melhorar para um crescimento ainda maior da visualização de dados. “Ainda somos muito ruins em comunicar incertezas”, declara a jornalista, que cita as projeções de eleições como exemplo.
Ela também alerta que o excesso de informação pode ser prejudicial, “com mais detalhes, teremos mais ruído para filtrar”. Tornar as visualizações mais acessíveis para todos os públicos, como deficientes visuais e daltônicos, foi outro ponto levantado por Gurman, ela diz que isso ainda não é incluído em muitas visualizações.
“O quarto ponto, e talvez o mais importante, é que as nossas ferramentas ainda não nos ajudam a atingir a variedade de dados”, declarou. Segundo ela, a procura e escolha dos dados usados deve ser relevante e interessante ao público. A variedade dos dados e perguntas que surgem a partir deles deve ser o foco principal, não o design do gráfico.
Após o fim da fala de Gurman, ocorreu uma entrevista, conduzida por Bárbara Castro, que abordou alguns dos assuntos da palestra, como a relação entre demonstração e interação nos gráficos. Bárbara também perguntou para Gurman se ainda é relevante saber como programar, já que hoje existem ferramentas que não necessitam de códigos. A audiência também enviou perguntas que foram respondidas pela palestrante.
Evento na íntegra: https://www.youtube.com/watch?v=OHDV7efi_VU
Quinta-feira
Workshop: 7 passos em 1: Como simplificar sua análise de dados com a Base de Dados
O penúltimo dia de workshops começou com o de nome “Como simplificar sua análise de dados com a Base dos Dados”. Adriano Belisário foi o mediador e Fernanda Scovino, Cientista de Dados na Secretaria de Transportes da Prefeitura do Rio de Janeiro e co-fundadora da Base dos Dados, foi quem apresentou a atividade.
O workshop consistiu na apresentação da Base dos Dados e na reprodução de uma análise, feita pela própria organização, sobre a variação dos preços dos combustíveis em relação à inflação. A Base dos Dados é uma organização sem fins lucrativos que pretende universalizar o acesso a dados de qualidade no Brasil.
Fernanda conta que Ricardo Dahis, também cofundador da Base dos Dados, encontrava algumas dificuldades na época de pesquisa: como encontrar os dados que precisava e como lembrar todas as características do que foi consultado. Para resolver esses problemas, começou a catalogar as bases de dados usadas. Em 2020 surgiu a ideia de publicar isso usando data lake, um sistema que armazena e centraliza os dados.
A cientista de dados pontuou os sete passos do processo de análise: achar os dados; baixá-los; carregá-los em outros programas; limpar formatações indesejáveis; cruzar dados com outras bases; processar o que foi feito e por fim, analisar o produto final.
A Base dos Dados reuniu os sete passos em um só lugar, através de três produtos abertos e gratuitos. O mecanismo de busca, que realiza os dois primeiros passos; o data lake público, que carrega, limpa e processa os dados, além de permitir ao usuário cruzá-los e analisá-los; também há os pacotes de acesso para quem já está mais familiarizado com a programação.
Fernanda apresentou o site e alguns recursos que estão disponíveis nele, também explicou como é o tratamento e a padronização feitos pela Base dos Dados. Após, a reprodução da análise da variação dos preços dos combustíveis começou.
O processo todo foi feito na plataforma Google Cloud, onde foram cruzados dados da Agência Nacional do Petróleo, Gás Natural e Biocombustíveis (ANP) com dados do Índice Nacional de Preços ao Consumidor Amplo (IPCA) sobre inflação, todos retirados do site da Base dos Dados. Os SQLs, comandos que executam ações em bancos de dados baseados em tabelas, também foram disponibilizados no site.
A análise consistiu em observar a variação do preço médio de venda de cada combustível, corrigido pela inflação. Com o processo de criação do código finalizado, Fernanda utilizou o data studio para a construção de um gráfico, para facilitar a visualização. A rodada de perguntas tratou de dúvidas sobre o funcionamento da Base dos Dados e questões sobre a reprodução da análise.
Workshop: Uso de imagens de satélite para detecção de queimadas
O workshop “Uso de imagens de satélite para detecção de queimadas” aconteceu na tarde da quinta-feira, das 14h às 15h30. Foi mediado por Anicely Santos e apresentado por Jorge Santos, especialista em Geotecnologias, produtor de Conteúdo Técnico e instrutor GIS. A atividade foi uma análise de detecção de queimadas a partir de imagens do satélite Landsat-8, usando software livre QGIS.
Após uma breve introdução sobre si, Jorge iniciou explicando como funciona o sensoriamento remoto. O sol irradia sobre a superfície terrestre, que reflete parte dessa radiação. Ao passar por essa superfície, o satélite detecta a intensidade de energia dessa reflexão e a quantifica em um código binário, que é transmitido para as estações de recepção do sinal. A estação entrega para o usuário final essa intensidade de energia quantificada em uma matriz, a imagem pronta para uso.
Em seguida, o instrutor apresentou alguns conceitos sobre o sensoriamento remoto e comentou sobre o espectro eletromagnético, instrumento que mede as ondas eletromagnéticas. Também contou a história e características da missão Landsat e do satélite Landsat-8, que gerou as imagens usadas para a prática. “É necessário conhecer o satélite que vai usar”, comentou.
Jorge iniciou a atividade apresentando o QGIS, que utiliza o sistema de camadas, parecido com o Photoshop. No primeiro momento, as imagens estão em escalas de cinza, para identificar queimadas é necessário fazer a composição RGB (Red, Green, Blue), organizando as camadas em faixas de cada cor. As áreas em roxo sinalizam áreas de queimada.
Para finalizar, o instrutor respondeu às perguntas feitas pelo público e também deu algumas noções básicas de interpretação das imagens geradas a partir do QGIS. Também mostrou ferramentas de como medir essas áreas.
Painel: Jornalismo de Dados no Mundo
No fim da tarde de quinta-feira (11), ocorreu a última palestra do dia. Tal palestra, que tinha como tema o Jornalismo de Dados no Mundo, marcou o lançamento da versão em português do “The Data Journalism Handbook: Towards a Critical Data Practice”, um livro referência para indivíduos da área que apresenta uma análise do Jornalismo de Dados no Mundo e traz certa perspectiva do cenário no futuro.
O evento, que foi mediado por Natália Mazotte – jornalista de dados, co-fundadora da Escola de Dados no Brasil e da revista digital Gênero e Número e líder do programa de jornalismo do Insper – e contou com a presença ilustre de Jonathan Grey, palestrante sênior em estudos de infraestrutura crítica no Departamento de Humanidades Digitais, King’s College London, Liliana Bounegru, professora de métodos digitais no Departamento de Humanidades Digitais do King’s College London, e Cédric Lombion, líder de dados e inovação da Open Knowledge Foundation.
Para iniciar as apresentações, Natália apresentou os convidados aos telespectadores e sintetizou o que seria abordado ao longo do painel. A primeira presença especial a iniciar a apresentação foi Liliana Bounegru, que falou sobre o livro “The Data Journalism Handbook: Towards a Critical Data Practice”. A professora falou que o livro está disponível de forma gratuita na internet em forma de pdf neste link . Liliana também falou sobre a construção do livro, os desafios e as maneiras que os autores encontraram as informações que foram inseridas no livro. Após a apresentação do livro, a professora falou sobre o jornalismo de dados apresentando notícias em veículos de informação na mídia, enfatizando o uso do Jornalismo de dados para causas feministas.
Logo em seguida, a mediadora Natália convidou Cédric Lombion para falar um pouco sobre a capacitação de profissionais dentro do Jornalismo de Dados. O líder de dados apontou o desequilíbrio que há no mundo entre os meios de comunicação do norte do país com os do sul, vendo que na parte norte, segundo o especialista, possui muitos mais recursos para profissionais terem acesso a tais informações. Cédric apontou a importância do investimento na democratização da informação, enfatizando a necessidade de vontade para fazer com que essa área se desenvolva, principalmente em faculdades. O aumento da força de vontade e disposição dos novos alunos de Cédric foi algo comentado durante a apresentação, que, segundo o especialista, traz esperanças para um melhor cenário no desenvolvimento do Jornalismo de Dados.
Após a apresentação de Cédric, Jonathan Grey falou sobre a diferença de verdades e dados, em que as pessoas podem ter suas verdades e essas verdades podem não coincidir com os fatos. Entretanto, o palestrante sênior apontou que isso pode prejudicar o desenvolvimento do Jornalismo de Dados, vendo que, segundo o mesmo, fatos e valores não podem ser separados, e sim devem ser analisados e interpretados.
Finalizando a apresentação, Liliana trouxe um outro ângulo na análise de Jornalismo de Dados, correlacionando o assunto abordado com o conteúdo presente no livro já apresentado.
Por fim, a mediadora Natália agradeceu a presença dos convidados e dos telespectadores e os convidados também agradeceram o convite.
Sexta-feira
Painel: Cobertura da crise climática
O último painel do Coda aconteceu na noite da sexta-feira e teve como tema a cobertura jornalística da crise climática. O mediador foi Gustavo Faleiro, editor da Rainforest Investigations Network (RIN) do Pulitzer Center. Laura Kurtzberg, professora assistente na Florida International University e líder de visualização de dados da Ambiental Media, Francy Baniwa, líder indígena, antropóloga e pesquisadora, e Clayton Aldern, repórter de dados sênior da Grist, revista sem fins lucrativos que cobre mudanças climáticas, justiça ambiental e soluções climáticas, foram os participantes do debate.
Gustavo introduziu com uma pergunta: “Qual é o papel do jornalismo de dados na prevenção e mitigação do colapso climático iminente?”. Também relacionou o painel com a realização da Cob 26 e adiantou que os participantes apontariam problemas e possíveis situações na área. Para a primeira parte do debate, questionou os participantes sobre a relação do trabalho de cada um com a crise climática e o uso de dados.
Laura foi a primeira a responder e disse que para ela os três fatores estão interligados, tanto nas aulas quanto nas pautas que participa. Clayton contou sobre seu trabalho na Grist e destacou que o papel da visualização de dados é tornar mais visível os impactos da crise climática. Francy comentou que a junção da visão dos cientistas com a dos indígenas é importante para a discussão do tema.
O próximo assunto levantado pelo mediador foi sobre os tipos de representação da crise climática. Laura exaltou a visualização de dados, que de forma artística, impacta o leitor. Clayton diz que a representação gráfica ajuda a atingir diversos públicos, de acordo com o contexto específico de cada um. Francy ressalta a comparação histórica que a visualização de dados, como mapas, permite. Ela destaca que os indígenas não têm tanto acesso a isso, mas por outro lado, sentem as mudanças.
Quais dados faltam para a cobertura climática foi a pergunta seguinte de Gustavo. Laura voltou ao primeiro comentário de Francy, falando sobre a importância da diversidade de participantes nas pesquisas. Clayton disse que é necessário fazer perguntas sobre questões étnicas para estabelecer um conjunto de dados e Francy citou a importância do calendário para as vidas indígenas. Segundo ela, a falta de dados de monitoramento sobre mudanças climáticas prejudica a rotina das comunidades.
Ao serem questionados sobre o papel do jornalista na transparência no cumprimento de metas climáticas, como as do acordo de Paris, Laura disse que o comunicador deve manter o interesse, atenção e cobrança do público além do fim de eventos e reuniões climáticas. Clayton definiu que a responsabilidade dos comunicadores é incluir experiências locais e contexto regional nos resultados desses encontros internacionais. Francy pontuou que o maior desafio é o acesso aos financiamentos voltados para os povos indígenas, que precisam ser acompanhados mais de perto.
O público perguntou formas de dimensão mais reais de impactos ambientais. Todos os participantes responderam que a alternativa mais eficaz para que o leitor entenda o tamanho desses impactos é a linguagem mais simples. O uso de contextos familiares e de comparações comuns, como campos de futebol ou cidades, facilitam a compreensão.
As representações artísticas de problemas reais, como o Covid-19, foram o tema de uma questão de Gustavo direcionada para Francy. A antropóloga declarou que dentro da narrativa indígena sempre há explicação para tudo e que a consulta com os mais velhos é sempre importante para entender esses processos.
Outra pergunta lançada por internautas foi se falta mais informação sobre justiça climática nos países em desenvolvimento, como o Brasil. Laura disse que não necessariamente há essa divisão, já que no Brasil existe uma cultura de monitoramento de queimadas e nos EUA não, por exemplo. Clayton concordou e acrescentou que faltam dados no mundo todo, o que causa falta de ação.
Uma telespectadora pediu que comentassem a relação do conhecimento científico ocidental com o tradicional indígena. Francy definiu como desafiador, que é necessário consultar e orientar indígenas na construção de dados e pesquisas sobre o território. “Têm muitas evidências de como isso torna uma história mais real”, comentou Laura. Clayton concordou e disse que é responsabilidade do jornalista oferecer a história completa, com todos os lados.
Adriano Belisário questionou se mapeamentos detalhados oferecem risco para populações locais e meio ambiente. Francy alerta que o objetivo e interesse do trabalho deve estar bem definido. Gustavo perguntou como os dados de redes sociais ajudam na comunicação da crise climática. Clayton falou que é necessário tomar cuidado com conclusões a partir de conjuntos de dados da internet, pois podem gerar desinformação. Laura contou que as mídias digitais auxiliam seus alunos na aprendizagem dos dados.
A última pergunta foi sobre qual o termo correto para nomear o momento. Gustavo contribuiu dizendo que “mudança climática” é o termo cientificamente mais aceito e que outras nomenclaturas podem ter viés. Clayton comentou que o termo usado deve ser pensado de acordo com o público-alvo.
Em seguida, cada um dos participantes deixou uma consideração final. Laura ressaltou que é papel do comunicador simplificar os dados para o público. Francy destacou a importância do jornalismo no processo, “é uma parceria que temos para a luta”, concluiu. Clayton disse que os métodos estatísticos são ferramentas do jornalismo. Gustavo encerrou o evento.
Evento na íntegra: Coda.Br 2021 | PAINEL: COBERTURA DA CRISE CLIMÁTICA
Sábado
Keynote: Machine Learning no Jornalismo de Dados

No sábado (13), último dia da Conferência Brasileira de Jornalismo de Dados e Mídias Digitais, ocorreu o keynote “Machine Learning no Jornalismo de Dados”. O evento, que foi mediado por Carolina Moreno, jornalista sênior de dados da TV Globo, contou com a presença de Sondre Solstad, jornalista sênior de dados da The Economist.
Para iniciar a apresentação, Carolina apresentou o convidado aos telespectadores e, logo em seguida, Sondre iniciou a palestra. O jornalista iniciou falando sobre como tentou descobrir os números reais da pandemia e, para a explicação, ele utilizou o aprendizado da máquina do Jornalismo de Dados. Sondre dividiu a palestra em duas partes, sendo a primeira delas responsável por mostrar como ele utilizou do método já abordado para estimar o número de mortos na pandemia, já a segunda parte foi utilizada para o jornalista apresentar diretrizes e sugerir dicas para a utilização do aprendizado de máquina no Jornalismo de Dados.
Durante sua apresentação, Sondre apontou dados de países para usar de exemplo, como os da África do Sul, em que o jornalista expôs a deturpação de dados em relação aos números da Covid-19 no país. A importância da checagem de dados também foi algo muito enfatizado por Sondre durante sua apresentação.
O jornalista, inclusive, explicou o que era o aprendizado de máquina, dizendo: “É uma área da estatística em rápido movimento”. Ou seja, quando a procura de dados é mais difícil e demanda um maior trabalho, pesquisadores e jornalistas dentro do campo de jornalismo de dados utilizam de máquinas para encontrar, com uma maior facilidade, os dados que necessitam.
Também foi apresentado por Sondre os motivos de usar o aprendizado de máquina no jornalismo, sendo eles:
- melhores ferramentas para questões já existentes;
- a possibilidade de realizar novas perguntas;
- a facilitação e melhoramento na investigação de indústrias e governos que já usam essa ferramenta em grande proporção.
Quando usar a ferramenta também foi algo apontado pelo jornalista, que sintetizou os momentos dizendo que o aprendizado de máquina deve ser utilizado quando for a melhor ou a única alternativa na busca por dados, quando utilizar diversos métodos em busca de um dado, para ter certeza qual é o melhor, e quando há a necessidade de abrir novas oportunidades, vendo que explorar ferramentas é fundamental para analisar a funcionalidade e possibilidade das mesmas.
Sondre, para finalizar sua apresentação, realizou uma perspectiva do futuro do aprendizado de máquina para o Jornalismo de Dados, dizendo que em cada ano a utilização do mesmo vem crescendo, portanto, estima-se que, cada vez mais, essa ferramenta de pesquisa e apuração irá crescer e se tornar mais presente em várias pesquisas.
Após a apresentação de Sondre, a mediadora Carolina leu algumas perguntas que os telespectadores realizaram ao jornalista. Em seguida, após a resposta de Sondre às questões levantadas pelo público, Carolina agradeceu a presença do jornalista e dos telespectadores. Sondre também agradeceu o convite.
Apresentações Relâmpago
A rodada de apresentações relâmpago aconteceu das 16h30 até 17h30 e teve como objetivo apresentar projetos inovadores baseados em dados, com apresentações de até dez minutos. Adriano Belisário foi o mediador do evento.
Antonio Oviedo, pesquisador do Instituto Socioambiental foi o primeiro a se apresentar. Ele representou o projeto Alertas+, uma plataforma com painel que monitora incêndios, desmatamento e garimpos ilegais na Amazônia, dentro e fora das áreas protegidas. Os dados são anuais e retirados de diversas organizações, dentre elas o Instituto Nacional de Pesquisas Espaciais (INPE) e a NASA.
A próxima foi Lia Barcellos, que apresentou a nova ferramenta desenvolvida pela Escola de Dados, a Caixa de Ferramentas do Jornalismo de Dados. O projeto é uma lista colaborativa de ferramentas, que oferece filtragem de ferramentas open-source e por categoria ou plataforma.

Representante da Diretoria de Transparência Ativa na Controladoria Geral do Estado de Minas Gerais, Francisco Alves mostrou o Data package manager for CKAN (dpckan). Isso é uma ferramenta utilizada para criação e atualização de conjuntos de dados e recursos, documentados de acordo com o padrão de metadados Frictionless Data em uma instância do CKAN.
A apresentação de Nicolle Cysneiros teve como tema discutir a relação de dados com grafos. Grafos é uma estrutura de dados G, formados por um conjunto de vértices V e um conjunto E de pares de arestas. Se trata de uma estrutura que permite representar relacionamentos entre os dados de forma mais explícita e oferece análises métricas diferenciadas.
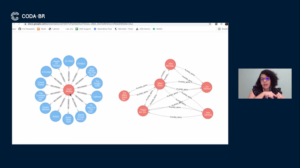
Nitai Bezerra da Silva apresentou o Ro-dou (Robô Minerador do Diário Oficial da União). Ele foi desenvolvido para “libertar as pessoas da tarefa manual de pesquisa no Diário Oficial da União” segundo Nitai. Se mostrou útil pois diversos departamentos do Ministério da Economia necessitam acompanhar nomeações, mudanças de estrutura, publicação de planos, dentre outros tipos de documentos oficiais. Trata-se de um Software Livre, utiliza AirFlow, plataforma de gerenciamento de fluxo de trabalho, como motor e é configurado através de YAML, um formato de serialização de dados legíveis por humanos.

Com o fim das apresentações, iniciou-se a rodada de perguntas da audiência para cada um dos participantes e representantes dos projetos. Também foram feitas considerações finais.
Prêmio Cláudio Weber Abramo de Jornalismo de Dados
A entrega do 3º Prêmio Cláudio Weber Abramo de Jornalismo de Dados marcou o encerramento do Coda.Br 2021. O evento iniciou às 19h e terminou às 21h, contou com a apresentação de Flávia Oliveira, comentarista GloboNews, colunista de O Globo e CBN e podcaster no Angu de Grilo.
Flávia introduziu chamando Fernanda Campagnucci, que relembrou algumas atrações apresentadas durante o Coda, em especial os painéis abertos e keynotes. Também fez agradecimentos à equipe e devolveu a palavra para Flávia. A jornalista falou sobre a história de Cláudio Weber Abramo, destacando seus feitos, pioneirismo no jornalismo de dados e sua participação na articulação da Lei de Acesso à Informação.
Por fim, Flávia contou que o prêmio seguiu uma lógica diferente de não estabelecer categorias prévias e destacou a diversidade de temas que isso proporcionou. Em seguida, iniciaram as apresentações dos 14 finalistas, com fala ou vídeos de três minutos para cada um.
Finalistas e vencedores:
Anatomia da Rachadinha (Vencedor)
Veículo: UOL
Autoria: Amanda Rossi, Flávio Costa, Gabriela Sá Pessoa, Juliana Dal Piva, René Cardillo, Leonardo Rodrigues, Marcos de Lima, Marcos Sergio Silva, Gisele Pungan
Trata da investigação do esquema ilegal nos gabinetes de Jair e Carlos Bolsonaro.
As Pensões e os Bilhões da Família Militar
Veículo: Piauí
Autoria: Taís Seibt, Bernardo Baron, Maria Vitória Ramos e Renata Buono
Aborda a imoralidade dos bilhões de reais pagos em pensões a parentes de servidores civis e militares que já morreram.
Bolsonaro não usou um terço dos recursos aprovados para políticas para mulheres desde 2019
Veículo: Revista AzMina
Autoria: Giovana Fleck e Naira Hofmeister
Traz uma análise sobre os recursos que o governo deixou de aplicar nos últimos anos.
Brasil registra duas vezes mais pessoas brancas vacinadas que negras
Veículo: Agência Pública
Autoria: Bianca Muniz, Bruno Fonseca, Larissa Fernandes, Rute Pina
Aborda as diferenças raciais na aplicação da primeira dose das vacinas contra Covid-19 no Brasil.
Engolindo Fumaça (Vencedor)
Veículo: InfoAmazonia
Autoria: Juliana Mori, Renata Hirota, Eduardo Geraque, Felipe Barros, Sonaira Silva, Tatiane Moraes, Guilherme Guerreiro Neto, Juliana Arini, Leandro Chaves, Camilo Estevam, Rebeca Navarro, Lucas Lobo, Leandro Amorim, André Hanauer, Erlan De Almeida Carvalho, Erico Rosa, Guilherme Lobo, Robson Klein Ramon Aquim, Dell Pinheiro, Laiza Lopes, Laura Sanchez, Tony Gross
Mostra os efeitos da poluição causada pelas queimadas na região da Amazônia Legal, e o impacto sobre a saúde da população local.
Existe uma Wakanda da política brasileira? (Vencedor)
Veículos: Data_labe + Alma preta
Autoria: Elena Wesley, Gabriele Roza, Paulo Mota, Estephany Nunes, Samantha Reis, Fred Giaccomo, Giulia Santos, Nicolas Noel, Vinicius Araujo e Yago Rodrigues
Traz uma análise dos municípios que tiveram maior representatividade negra nas eleições de 2016.
Inocentes presos (Vencedor)
Veículo: Folha de S. Paulo
Autoria: Artur Rodrigues, Rogério Pagnan, Rubens Valente, Henrique Santana, Karime Xavier, Luciano Veronezi, Pilker, Thiago Almeida
Faz um levantamento sobre o encarceramento de pessoas que foram vítimas de reconhecimentos errados.
Monitor Nuclear (vencedor da categoria inédita Menção Honrosa)
Veículo: Núcleo Jornalismo
Autoria: Sérgio Spagnuolo, Lucas Gelape, Felippe Mercurio, Renata Hirota, Lucas Lago, Rodolfo Almeida, Jade Drummond e Alexandre Orrico
Ferramenta gratuita de identificação e monitoramento de perfis de políticos brasileiros no Twitter.
Monitoria (Vencedor)
Veículos: Revista AzMina e InternetLab
Autoria: Bárbara Libório, Helena Bertho, Carolina Oms, Thais Folego, Jamile Santana, Larissa Ribeiro, Carolina Herrera, Mariana Valente, Fernanda Martins, Alessandra Gomes, Blenda Santos, Catharina Pereira, Jade Becari, Sérgio Spagnuolo, Renata Hirota, Yasmin Curzi, Katia Brasil, Roberta Brandão, Nay Jinkss, Juliana Costa, Camila Souza, Laércio Portela, Ana Beatriz Felício, Halitane Rocha, Lucas Rodrigues, Lucas Veloso, Morgani Guzzo, Inara Fonseca, Juliana Rabelo, Vandreza Amante, Paula Guimarães, Beatriz Lago, Karoline Gomes, Andreza Miranda, Jordânia Andrade, Maira Monteiro, Moisés Teodoro, Sofia Leão, Thiago Ricci, Vitor Fernandes, Vitor Fórneas
Coletou e analisou comentários feitos nas redes sociais direcionados às candidatas que concorreram às eleições de 2020.
O ‘Carro da Linguiça’ e outras chacinas sobre rodas que exterminam a periferia e o governo ignora
Veículo: The Intercept Brasil
Autoria: Gabrielli Thomaz, Mayara Mangifeste, Carlos Nhanga, Cecília Olliveira
Aborda as estatísticas de um padrão de ataque realizado em todo Brasil.
O Facebook não morreu
Veículo: Núcleo Jornalismo
Autoria: Alexandre Orrico, Rodolfo Almeida e Sérgio Spagnuolo
Mostra as tendências de crescimento do relacionamento em grupos na rede social.
Onde vai parar o lixo reciclável
Veículo: Metrópoles
Autoria: Lucas Marchesini, Lilian Tahan, Priscilla Borges, Otto Valle, Olívia Meireles, Juliana El Afioni, Gui Prímola, Marcos Garcia, Gabriel Foster, Daniel Ferreira, Michael Melo, Igo Estrela, Rafaela Felicciano, Allan Rabelo, Daniel Mendes, Italo Ridney e Saulo Marques
Traz os resultados da investigação sobre os caminhos traçados pela coleta seletiva no Distrito Federal.
Telegram, o novo refúgio da extrema direita
Veículo: Núcleo Jornalismo
Autoria: Sérgio Spagnuolo, Renata Hirota, Felippe Mercurio, Lucas Gelape, Rodolfo Almeida e Alexandre Orrico
Relata para onde os discursos de políticos extremistas têm migrado diante das políticas contra desinformação das maiores redes sociais.
Um ano depois, assassinatos durante motim da PM seguem sem esclarecimento
Veículo: O Povo
Autoria: Lucas Barbosa de Araújo
Traz um levantamento sobre os homicídios ocorridos em Fortaleza entre fevereiro e março de 2020.
Fernanda Campagnucci encerrou a cerimônia de premiação e também a sexta edição da Conferência Brasileira de Jornalismo de Dados, o CODA.BR, agradecendo a todos que participaram do evento e à equipe que os produz.
Evento na íntegra: Coda.Br 2021 | PRÊMIO Cláudio Weber Abramo DE JORNALISMO DE DADOS







{kind=link}